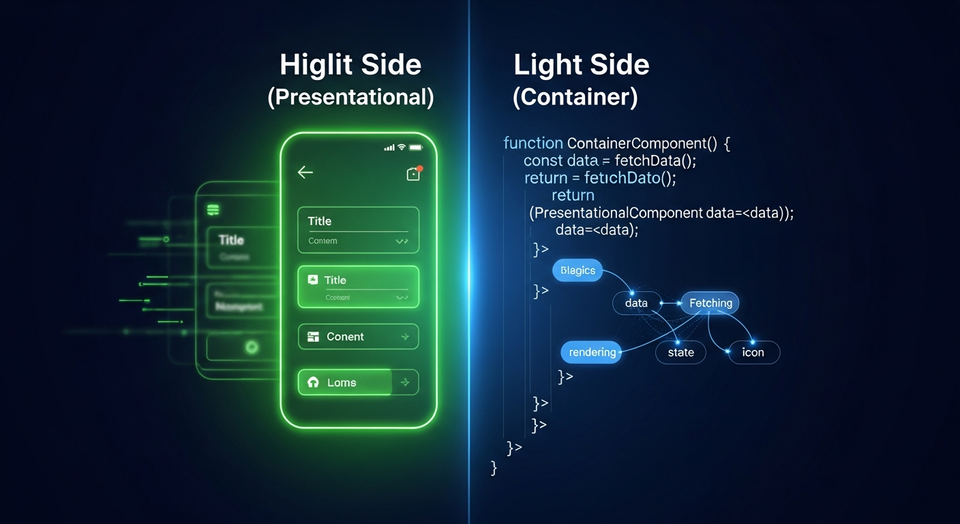
By Thisara Priyamal in Pandas — 01 Nov 2025 Pandas Groupby & Aggregation | Python Data Science Sinhala Tutorial