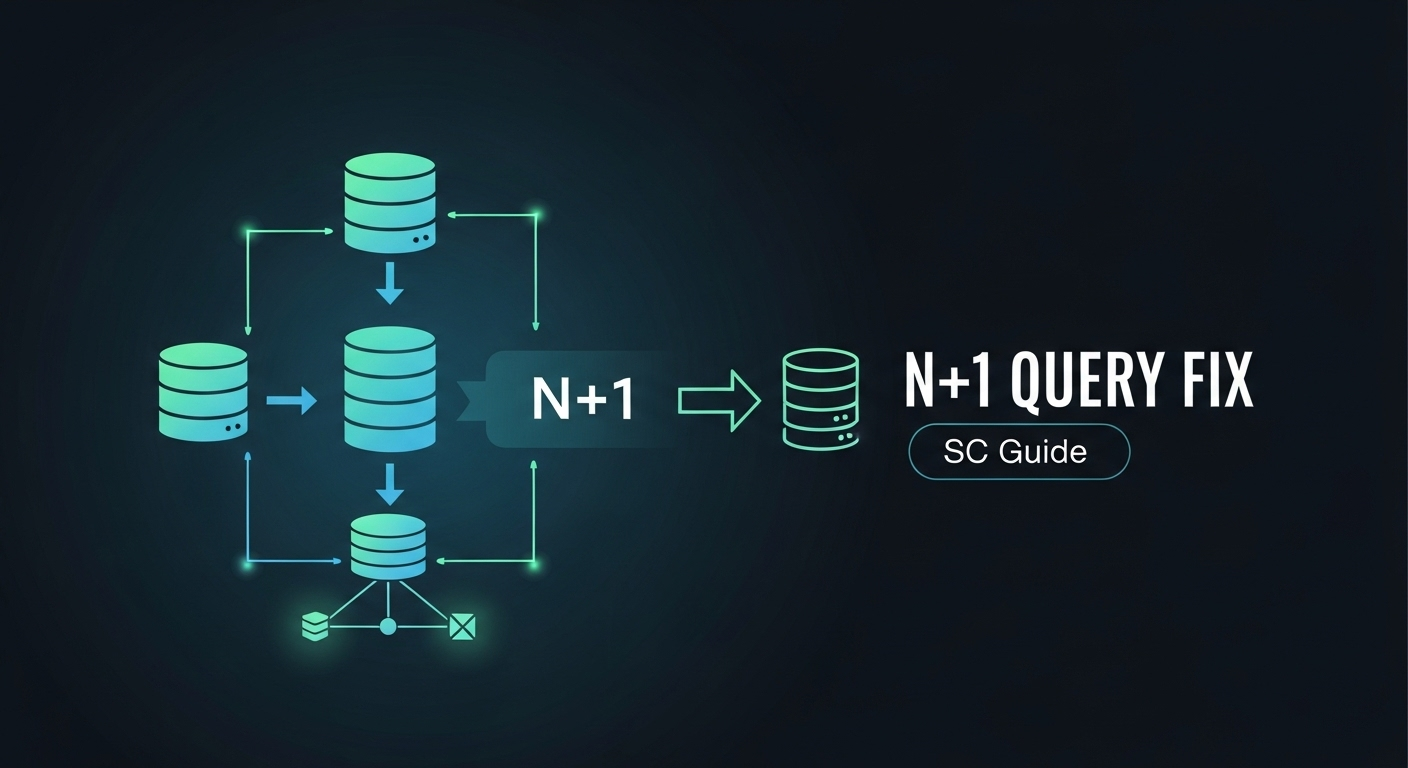
By Thisara Priyamal in JPA — 05 Jul 2025 JPA N+1 Query Problem Sinhala Guide | Hibernate Performance Optimization | N+1 ප්රශ්නය විසඳමු