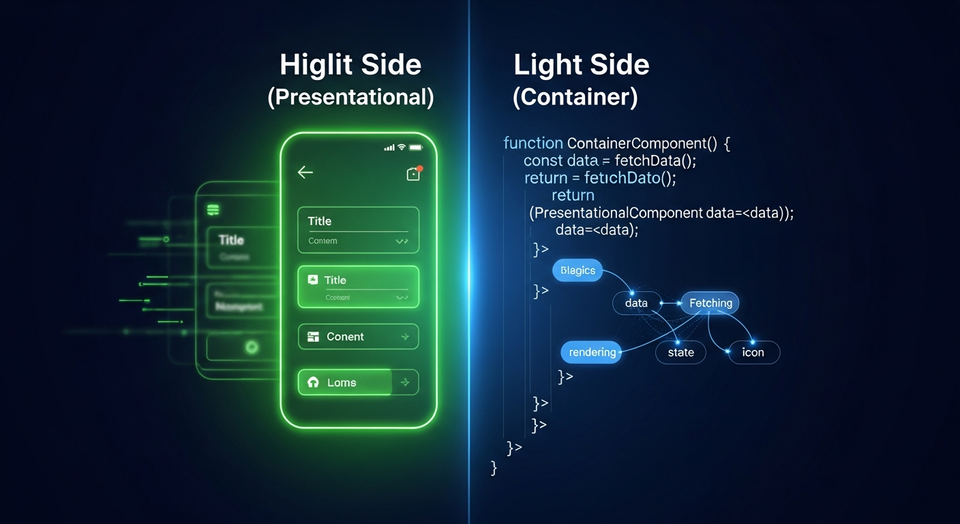
By Thisara Priyamal in AWS AI — 13 Oct 2025 AWS AI Model Deployment & Inference - Real-time, Batch, A/B Testing | Sinhala Guide